It is hard to recall – still less to imagine, if you weren’t there – the ferment of innovation between the late ’80s and the mid-’90s. By 1993 the World Wide Web – which was only invented in 1989 – was beginning to show its potential. Personal computers were now portable and more accessible, while in 1992 Nokia had launched a small mobile phone. These innovations presented major challenges and opportunities to the OU as the global leader in open learning. The new VC, John Daniel, could see that the devices and technology now emerging in homes and offices from this ferment, would determine how the OU taught its students.
The OU already had working examples of the possibilities of IT and media innovations in learning and teaching, notably in the work of Tom Vincent of METG (Multi-media Enabling Technologies Group in IET) and Marc Eisenstadt of HCRL (Human Cognition Research Lab in Psychology). METG focussed on using technology to enable those with special needs to have full access to study material on the internet and had found that what worked for those with special needs also worked well for everyone else. HCRL had been working in the intersections of Cognitive Science, Artificial Intelligence (AI) and Human Computer Interaction (HCI). Notably, the HCRL team had taken part in the Alvey programme, the first ever UK strategic R&D initiative focused on AI, and they had also produced the first OU courses that covered AI topics. And both groups were using communications technologies to bring people together remotely to interact, collaborate and learn.
These groups and Kitty Chisholm, Director of Development, came together to discuss the greater leverage that closer collaboration might bring. Marc Eisenstadt envisioned a ‘leading edge outpost of the OU’ and Tom Vincent drew a diagram on a napkin of how the new unit’s space should be configured to promote interdisciplinarity, cross-fertilisation and innovation. The idea of an innovation lab, on the model of the MIT Media lab, was born. KMi’s research would not only harness the latest technologies to improve learning and teaching but would be based on fundamental research on human cognition, knowledge representation, learning and collaboration at the individual and organisational levels. External and internal funding would be tapped.
The next challenge was to make it happen. Marc, Tom and Kitty drafted a concept paper, asking permission for a pilot. This got an encouraging nod and a request for a business plan from the VC, John Daniel, who already understood that the OU’s key challenge for the future was to combine global technological leadership and academic quality in an increasingly competitive distance learning environment. The two groups started to work together under the Knowledge Media umbrella.
Meanwhile, the Higher Education Reform Act of 1992 had given the OU greater budgetary freedom and control over its future. Taking advantage of this new context, in January 1995 the VC presented ‘Integrating New Systems and Technologies into Lifelong Learning’ (INSTILL), a plan to invest £10 million in the application of technology in teaching and learning to prepare the OU for the 21st century. The creation of the Knowledge Media Institute (KMi) was a core element of this transformational initiative.
Marc and Tom concluded that the only way to make such a new unit a reality was to bring their teams together in one place so that the cross-fertilisation of ideas could happen naturally. They identified a portacabin – to be known as ‘the hut’ – to be set up, after approval for funding from the VC, as a hollow square surrounding an atrium – mirroring Tom’s napkin design. They also put up a flagpole flying a new name – KMi – Knowledge Media Institute (or as Tom had it – Kitty, Marc and I).
From the outside, some of the early projects projected a magical air. Tom and Peter Whalley were a powerhouse of original ideas, assisted by a devoted METG team including Jon Linney, Kevin Quick, Chris Valentine and Ben Hawkridge. The Virtual Field Trip was developed for students unable to undertake site visits for earth sciences courses. Peter Whalley’s Virtual Microscope is still used by students on some courses, and his other remote-teaching experiments – like a virtual bicycle pump and a viscosity demo that calibrated mouse speed to mimic different liquids –were fun and effective. Perhaps the most striking example was First Flight, a simulation of the Wright Brothers’ first successful attempt. Its teaching of the physics of flight was so realistic that it sparked rumours that there was film footage of that momentous event. The lab later developed several projects with schools. The first linked three local schools to the web, via a relay dish on the top of the tallest church in Milton Keynes and a transmitter dish on the KMi roof. This enabled the virtual Mars Buggy project, which the children could control remotely in a simulated Mars environment – where they were joined by the occasional NASA scientist! Another involved 40 schools and 300 parents, who were shown how to use a computer to capture their local history projects, with funding by the Millennium Commission of £0.72 million.
Thanks to INSTILL funding, KMi attracted brilliant researchers from UK, Europe and the US, including Peter Scott, Simon Buckingham Shum, Tammy Sumner and Marco Ramoni. These arrivals injected new momentum and created new directions of research. Telepresence projects evolved from 1994’s Virtual Summer School and a virtual seminar series called KMi Maven of the Month (the first international Internet Talk Radio), to Stadium (still used today) and Peter Scott’s Virtual Pub Quiz. The aim was to create a sense of ‘being there’. Marco Ramoni, a Bayesian mathematician working at the intersection of Big Data and Machine Learning, where AI is making headlines today, focused on identifying potential, as yet unrecognised, causes of heart attacks from large, incomplete, data sets. At the same time, Simon Buckingham Shum started to develop new platforms to enable collaboration on the web, working with NASA and other organizations, while Tammy Sumner also tackled issues of collaboration and knowledge sharing in large, distributed organizations. Also, on the front lines of AI at that time, Enrico Motta, John Domingue, and Zdenek Zdrahal were reimagining how knowledge could be represented, shared, and reused in the emerging online world. Enrico developed methods for combining reusable chunks of expert knowledge, while John explored ways to give web content a layer of meaning that computers could interpret, and Zdenek showed how to capture and adapt expert problem-solving strategies for new situations, including early detection and intervention strategies for helping potentially failing OU students. This was just one example of how KMi worked with the OU faculties to advance their core mission of teaching and learning with new technologies. By the end of the ’90s KMi was involved in over a dozen OU course teams and was fulfilling its original mission by collaborating in a wide range of research, teaching and presentation initiatives across the OU.
Those early days also attracted significant donations of equipment from organisations like Sun Microsystems and Apple, with 70% of KMi income coming from external sources (commercial as well as foundations and traditional research funders such as Research Councils). As the lab grew and its projects became more complex, Jez Grzeda joined and was instrumental in keeping motivation and growth going, taking on all admin, finance and business development tasks.
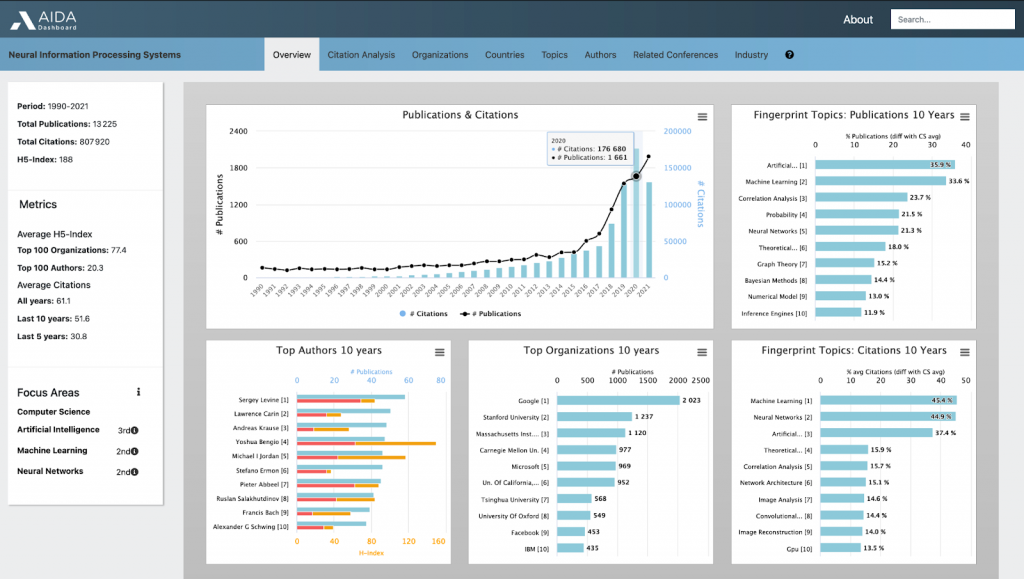
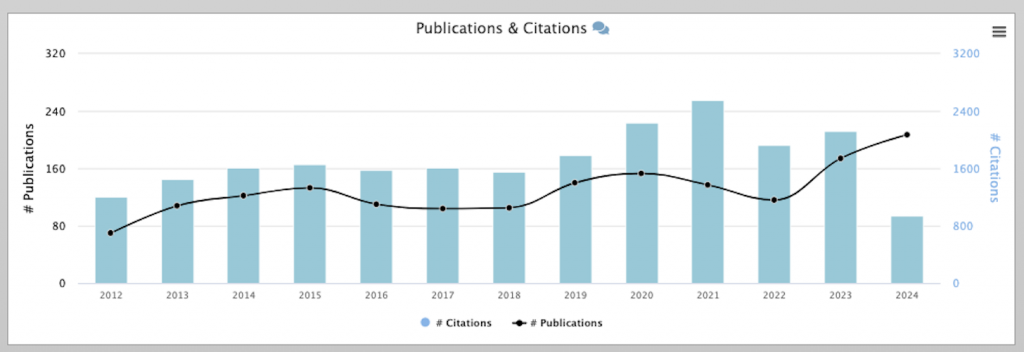
KMi’s research has had a profound and lasting impact, both nationally and internationally. Formal research metrics and external recognition confirm this influence, but perhaps the clearest evidence lies in how its ideas have helped shape the very fabric of the digital world. For example, from the late 1990s onwards, under the leadership of Enrico Motta and John Domingue, KMi played a pioneering role in the Semantic Web – years before Sir Tim Berners-Lee’s seminal 2001 paper. Collaborating with European and global leaders, KMi’s research contributed to foundations that, by 2012, were taken up by Google as the ‘Knowledge Graph,’ and soon after adopted by every major technology company. Today, some of the standards driving the Web can be traced directly to that early KMi work.
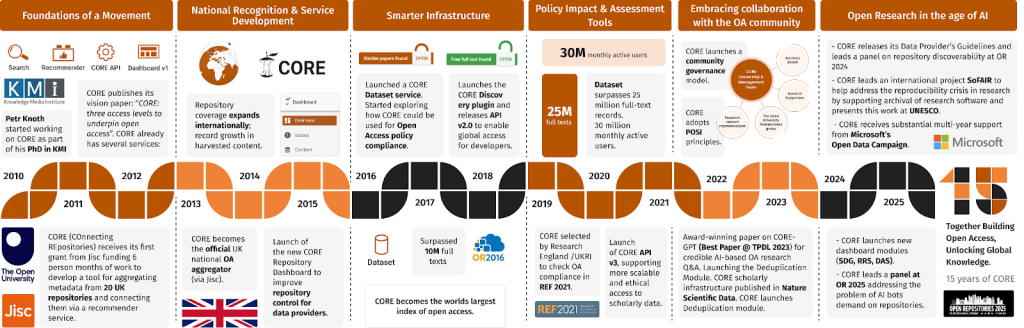
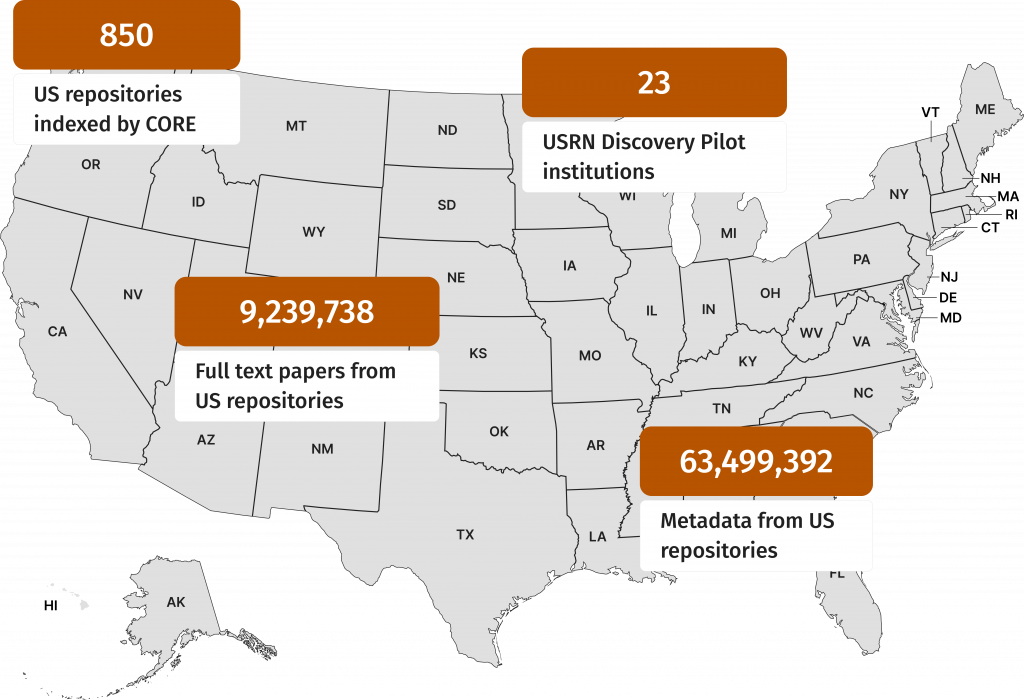
In 2010–11 KMi launched CORE, led by Petr Knoth, and OU Analyse, originally led by Zdenek Zdrahal. CORE has grown into the world’s largest open-access research paper collection and won five years’ Google funding in 2024. OU Analyse, now led by Miriam Fernandez, has delivered roughly £2.5 million per year in savings to the OU over the past three academic years by boosting student retention.
The present boom in Generative AI feels strikingly similar to the wave of innovation that defined the late ’80s and early ’90s. There is enormous potential to deliver even greater value – enhancing lifelong learning and extending access to education across the globe. True to its founding mission, KMi continues to innovate ahead of the curve, developing and testing ideas before they rise to wider public recognition.
This blog post has been authored by: Kitty Chisholm, Marc Eisenstadt, Tom Vincent and John Daniel with input from John Domingue, Enrico Motta, Peter Scott and Miriam Fernandez.